
[JPA] N+1
1. N+1 문제
- JPA라는 ORM을 사용하기 때문에 SQL(JPQL)을 작성할 필요가 없다.
하지만, ORM도 결국 데이터베이스와 소통을 대신할 뿐 어느 시점에 SQL을 데이터베이스에 전달한다.
>> spring.jpa.show-sql 설정을 true로 설정하면 Hibernate가 실제 실행하는 쿼리문을 볼 수 있다.
- studentRepository.findAll();을 실행하면?
@GetMapping("simple-find")
public String simpleFind() {
studentRepository.findAll();
return "done";
}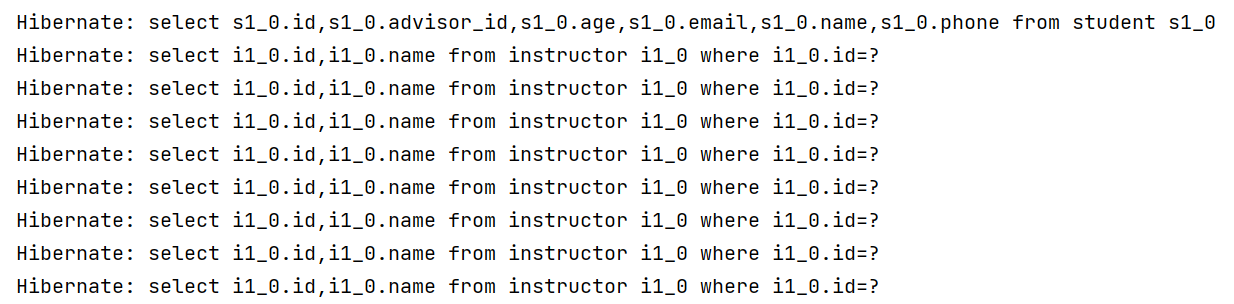
: Student만 조회하려고 하지만, Instructor도 조회하려는 SQL이 있다. 왜냐하면 Student 엔티티 내부의 Instructor를 찾으려고 하면서 발생한다. (영속성 컨텍스트로 인해 이미 조회했던 데이터는 다시 검색하지 않기 때문에 중복되지 않는 Instructor만큼 실행됨)
- 1) 전체 Student Entity N개를 조회하는 1번의 쿼리
- 2) Student와 연관된 Instructor를 위한 N번의 쿼리
- Instructor가 가진 List<Student>를 사용할 때에도 문제가 생긴다.
@GetMapping("simple-find")
public String simpleFind() {
List<Instructor> instructors= instructorRepository.findAll();
for (Instructor instructor : instructors) {
log.info(String.format("advising student count : {}",
instructor.getAdvisingStudents().size()));
}
return "done";
}
: 각각의 Instructor를 조회하면서 해당 Instructor를 advisor로 가진 Student를 조회하기 위해서 id를 advisor_id로 가지는 Student를 조회하는 SQL이 발생한다.
- 1) 전체 Instructor Entity N개를 조회하는 1번의 쿼리
- 2) 각각의 Instructor와 연관된 Student를 위한 N번의 쿼리
- SQL에서는 이런 경우에 JOIN을 활용하지만, JPA는 성능을 위해서 굳이 나누어서 SQL을 작성하고 실행한다.
이유는 상황에 따라 필요한 데이터를 나중에 조회하기 위해서!
- ManyToOne 관계 Entity : Proxy 객체
- OneToMany 관계 Collection : PersistentBag
즉, 아이러니하게도 성능 향상을 위한 기능을 위해,,, 성능을 저하시키는 상황이다
이렇게
N개의 데이터를 조회할 때 N+1번의 쿼리가 실행되는 문제를 "N+1문제"라고 부른다!
2. 즉시로딩, 지연로딩
- N+1 문제는 어느 시점에 데이터를 가져오느냐의 문제이다.
ex) Student 전체 조회의 경우에는 특별히 Instructor를 사용하지 않아도 필요이상의 SQL이 발생함.
Instructor의 경우는 Student를 사용하는 시점에 문제가 발생함.
>> 이유는 ? @ManyToOne, @OneToMany의 FetchType (로딩 방식)이 다르기 때문이다!
- 로딩 방식
1) 즉시 로딩(Eager Loading)
: 데이터를 불러오는 시점에서 연관관계에 있는 데이터를 전부 불러오는 방식.
이론적으로는 필요한 데이터를 한 번에 가져오는 용도지만,,,, 실제로는 전체조회 쿼리 한번, 필요한 연관 데이터를 위한 쿼리 N번 (N+1)이 발생하게 된다.
- @ManyToOne 기본값
ex) Student를 불러오는 시점에 Instructor 불러옴.
2) 지연 로딩(Lazy Loading)
: 연관관계의 데이터가 필요한 시점(해당 데이터가 사용되는 시점)에 불러오는 방식.
- @OneToMany 기본값
ex) Instructor를 불러오는 시점에는 Student 조회 X / advisingStudents 실제 데이터를 활용하는 시점에 로딩.
- 설정
1) 즉시 로딩 : FetchType.EAGER
2) 지연 로딩 : FetchType.LAZY
@ManyToOne(fetch = FetchType.LAZY)
@Setter
@JoinColumn(name = "advisor_id")
private Instructor advisor; @GetMapping("fetch-type")
public String fetchType() {
List<Student> students = studentRepository.findAll();
log.info("==============");
for (Student student : students) {
if (student.getAdvisor()!=null) {
log.info("{}", student.getAdvisor().getClass());
log.info("{}", student.getAdvisor().getName());
}
}
return "done";
}
>> studentRepository.findAll(); 에서는 1개의 쿼리를 발생한다.
이후 실제로 각각의 Student 객체에서 불러들일 때 N개의 쿼리가 실행되며 나온다.
@GetMapping("fetch-type")
public String fetchType() {
List<Student> students = studentRepository.findAll();
log.info("==============");
for (Student student : students) {
if (student.getAdvisor()!=null) {
log.info("{}", student.getAdvisor().getClass());
log.info("{}", student.getAdvisor().getId());
}
}
return "done";
}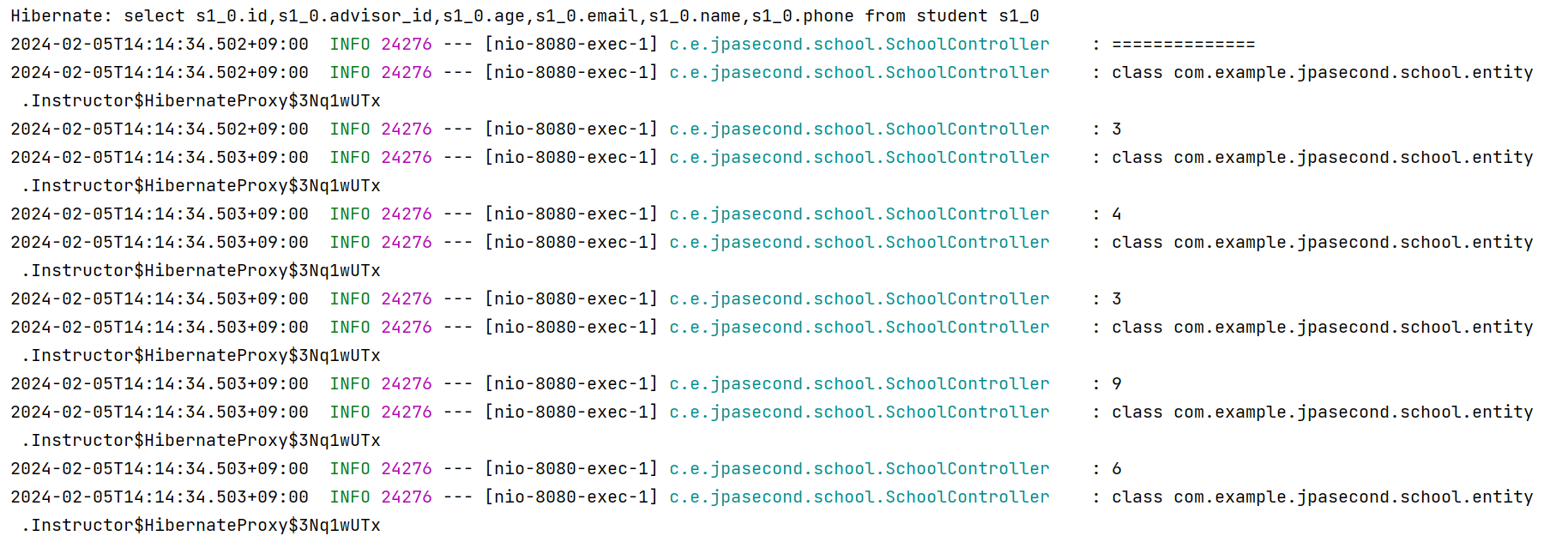
>> advisor_id(FK)를 조회하는 것은 이미 불러왔기 때문에 N+1을 발생시키지 않는다! (추가적인 SQL 실행 없이 결과값이 출력된다)
3. Join해서 가져오기
: 좀더 본질적인 해결책으로 Join을 통해서 해결할 수 있다.
이때 JPQL로 조인이 가능하다.
- JPQL JOIN
// (INNER) JOIN (양쪽 모두 NULL이 아님)
@Query("SELECT s FROM Student s JOIN s.advisor")
List<Student> findAllJoin();
// LEFT (OUTER) JOIN (왼쪽 누락X, 오른쪽 NULL 있음)
@Query("SELECT s FROM Student s LEFT OUTER JOIN s.advisor")
List<Student> findAllLeftJoin();
// RIGHT (OUTER) JOIN (오른쪽 누락X, 왼쪽 NULL 있음)
@Query("SELECT s FROM Student s RIGHT JOIN s.advisor")
List<Student> findAllRightJoin();: 두 엔티티의 데이터를 전부 가져오지 않고, 실제로 선택한 엔티티 (Student)만 가져온다. 연관관계의 엔티티는 Proxy가 들어온다 (Instructor) => Instructor의 데이터가 필요한 상황이 아닌 Instructor 데이터를 기준으로 조회하는 경우 사용.
실제로 연관관계의 데이터를 가지고 오고 싶다면.....!?
1) Fetch Join
: Fetch Join을 하면 한 번의 쿼리로 모든 데이터를 불러와 N+1 문제를 피할 수 있다.
- 중복 제거를 위해 DISTINCT와 함께 사용한다.
@Query("SELECT DISTINCT s FROM Student s JOIN FETCH s.advisor")
List<Student> findFetch();
@Query("SELECT DISTINCT s FROM Student s LEFT JOIN FETCH s.advisor")
List<Student> findLeftFetch();
@Query("SELECT DISTINCT s FROM Student s RIGHT JOIN FETCH s.advisor")
List<Student> findRightFetch(); @GetMapping("fetch-join")
public String fetchJoin() {
List<Student> students = studentRepository.findAllFetchAdvisor();
for (Student student: students) {
student.getAdvisor().getName();
}
return "done";
}
>> 결과를 보면 쿼리는 딱 한 번만 실행하고, 모든 데이터를 불러들일 수 있다.
2) @EntityGraph
로도 N+1 문제를 해결할 수 있다.
- EntityGraph는 실행 중에 조절할 수 있는 동적 방법이다.
cf) 엔티티 속성에 붙이는 어노테이션의 fetch옵션은 정적 방법이다. 엔티티 생성 시에 적용이 되어 고정되어 있다.
- @EntityGraph의 목표는 FetchType을 "실행할 때" 결정하는 것!
그러니, 보통의 경우에는 거의 LAZY 타입으로 설정되어 있고, 어떤 특별한 순간 (EAGER 타입으로 한 번에 불러들이는 것이 나은 경우)의 메서드에서 사용하여 EAGER 타입으로 만든다! 라고 생각해 보자.
@EntityGraph(attributePaths = {"advisingStudents"}, type = EntityGraph.EntityGraphType.FETCH)
@Query("select distinct i from Instructor i")
List<Instructor> findByEntityGraph();- attributePaths 옵션 : 어떤 속성에 적용할지를 결정
- type으로 로딩 결정 방식을 설정.
- EntityGraphType.FETCH : 지정된 속성들을 EAGER로 설정하고, 그 외의 속성들은 LAZY로 설정
- EntityGraphType.LOAD : 지정된 속성들을 EAGER로 설정하고, 그 외의 속성들은 기본값/ 설정된 값으로 활용.
@GetMapping("entity-graph")
public String entityGraph() {
List<Instructor> instructors = instructorRepository.findByEntityGraph();
for (Instructor instructor : instructors) {
log.info("{}", instructor.getAdvisingStudents().size());
}
return "done";
}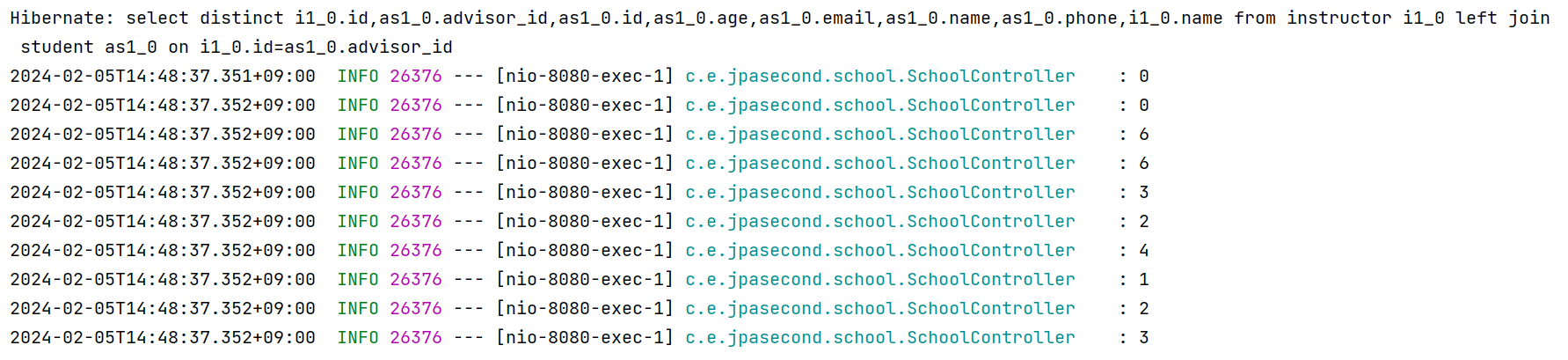
>> Instructor 리스트를 불러들여서 각각의 Instructor 객체의 정보를 출력하는데, 이것을 한 번에 해줘라!라고 @EntityGraph로 붙여주면 하나의 쿼리로 내용을 불러들인다! 이때 속성이름을 적어주어야 함.
- 기존에 있는 findAll() 메서드도 오버라이딩하여 사용 가능하다.
ex) 이번에는 Student에서 @ManyToOne으로 맵핑된 advisor 속성을 가져와보자.
// Controller class
@GetMapping("findAll")
public String entityGraphFindAll() {
List<Student> students = studentRepository.findAll();
log.info("=======================");
for (Student student : students) {
if (student.getAdvisor() != null) {
log.info("{}", student.getAdvisor().getName());
}
}
return "done";
}
- @EntityGraph 적용 전
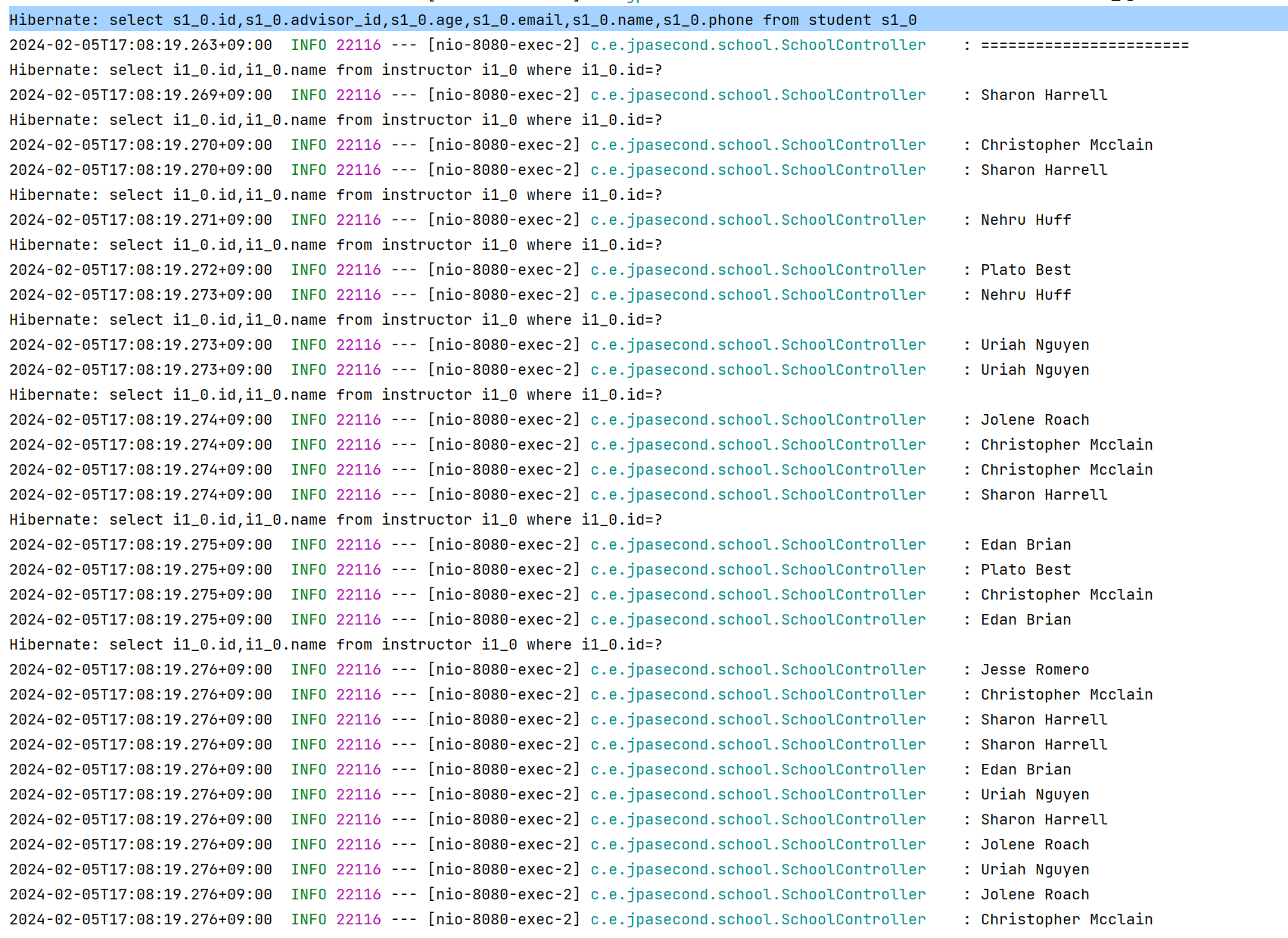
>> N+1문제가 나오고 있다. 전체 쿼리 1개 + instructor마다 하나씩 N개
- @EntityGraph 적용 후
@EntityGraph(attributePaths = {"advisor"}, type = EntityGraph.EntityGraphType.FETCH)
List<Student> findAll();
>> 짠! 이렇게 한 번의 쿼리로 전체 Student의 Advisor 이름이 나오고 있다!
3) MultipleBagFetchException
- 단, 두 개 이상의 Collection 속성을 attributePaths에 설정하게 되면 List를 사용하는 경우 MultipleBagFetchException이 발생하게 된다.
@EntityGraph(attributePaths = {"advisingStudents", "lectures"}, type = EntityGraphType.FETCH)
@Query("SELECT i FROM Instructor i")
List<Instructor> mulitBagFetch();@GetMapping("multibag-fetch")
public String multiBagFetch() {
log.info("실행 =======================");
List<Instructor> instructors = instructorRepository.mulitBagFetch();
log.info("=======================");
for (Instructor instructor : instructors) {
log.info("advisingStudent count: {}", instructor.getAdvisingStudents().size());
log.info("lectures count: {}", instructor.getLectures().size());
}
return "done";
}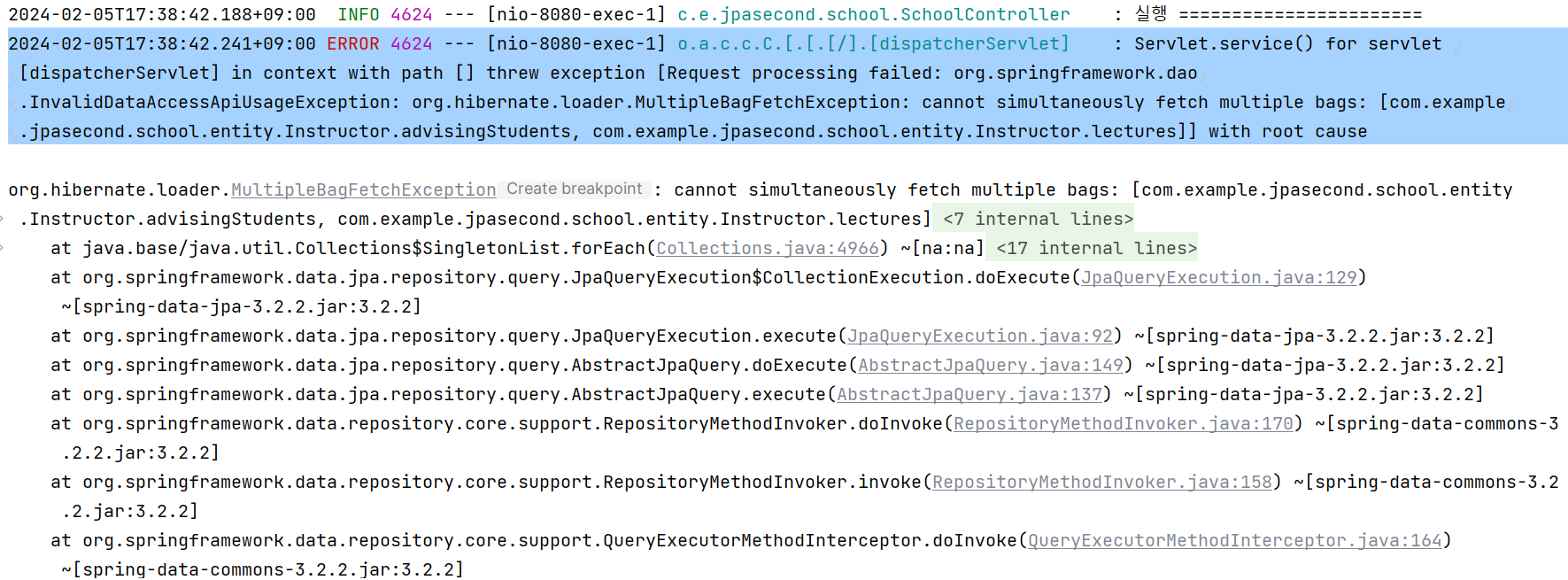
> 이렇게 cannot simultaneously fetch multiple bags Exception이 발생한다.
: 이는 하나의 엔티티(One)가 두개 이상의 속성에 대해서 ToMany를 가지게 될 경우
결과적으로 두 연관관계에 대해 곱집합을 만들게 되며 One에 해당하는 엔티티 쪽의 Many 엔티티들의 순서를 결정할 수 없어서 발생하는 문제이다.
4. @BatchSize
- Fetch Join / @EntityGraph 둘 다 N+1 문제를 해결 가능하지만, 페이징 처리를 할 때 문제가 발생하게 된다...
- Fetch Join 하면서 Pageable을 매개변수로 하여 페이징 처리를 해보자.
@Query("select distinct i from Instructor i left join fetch i.advisingStudents")
Page<Instructor> findByFetchPagination(Pageable pageable);
@GetMapping("fetch-paging")
public String fetchPagination() {
Page<Instructor> paging = instructorRepository.findByFetchPagination(PageRequest.of(0, 4));
return "done";
}
>> 페이징 처리 시 경고가 뜨면서 실행되는 SQL 쿼리에 LIMIT, OFFSET이 없는 채로 실행이 된다.
즉, FETCH 조인을 썼는데, 페이징 쿼리가 들어가서 메모리에서 페이징 처리를 하겠다는 경고이다. 전체 데이터를 쿼리로 먼저 불러온 다음, 연관관계를 데이터베이스에서 처리하는 게 아닌, JPA에서 처리를 한다는 의미이다.
작은 데이터는 상관이 없겠지만, 데이터가 크면 out of memory가 뜰 수밖에 없다.
1) 일단 지연로딩으로, 연관관계를 가져오지 않고 페이징 처리를 한다.
2) 연관관계를 가져올 때 가져와야 하는 연관관계 데이터를 한 번에 여러 개 가져온다.
@BatchSize를 적용하면 지연로딩할 때 가져올 데이터의 개수를 정할 수 있다.
// Instructor Entity class
@BatchSize(size = 5)
@OneToMany(mappedBy = "advisor", fetch = FetchType.LAZY)
private final List<Student> advisingStudents = new ArrayList<>(); @GetMapping("fetch-paging")
public String fetchPagination() {
log.info("실행 =======================");
instructorRepository.findAll(PageRequest.of(0, 10))
.forEach(instructor -> System.out.println(instructor.getAdvisingStudents().size()));
return "done";
}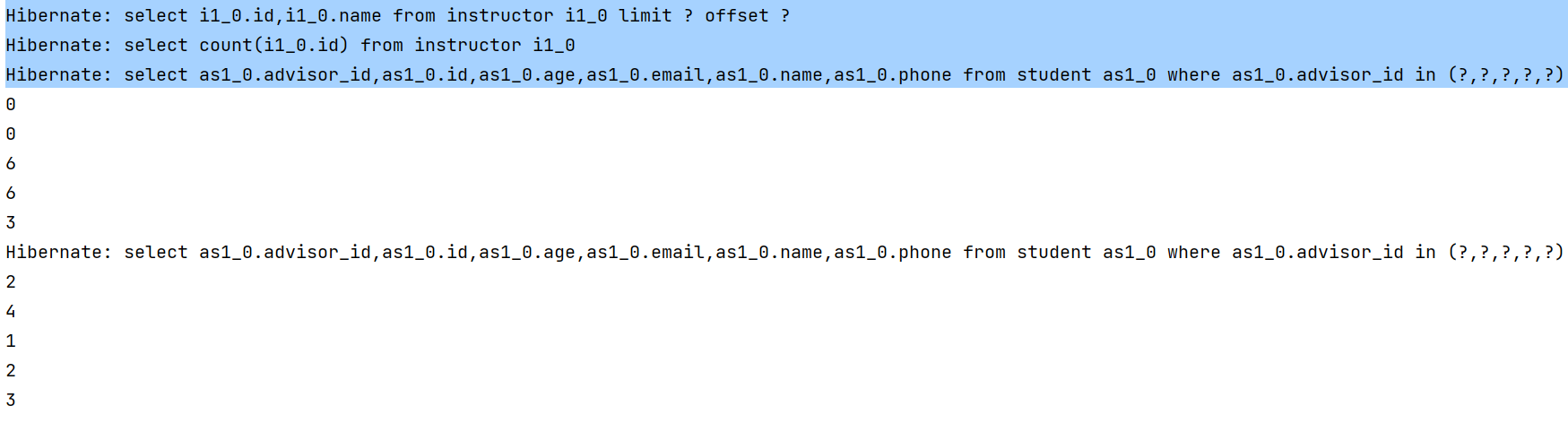
총 쿼리 실행은 4번
1) limit, offset과 함께 전체 조회
2) 전체 페이지 확인을 위한 count 쿼리
3&4) @BatchSize로 인해 정해진 수량만큼의 Instructor를 기준으로 Student 검색
- 즉, 지연로딩을 유지하면서 실제 로딩이 필요한 시점에 정해진 수량만큼 한 번에 로딩함으로써 N+1 문제를 완화하면서 페이징 처리도 가능하게 된다.
총정리!
N+1문제 ? JPA라는 ORM 프레임워크를 사용할 때 상황에 따라 필요한 데이터를 조회하도록 만들어져 오히려 N+1번 데이터를 조회하는 SQL 쿼리를 사용하는 문제. (전체 엔티티 조회 1번, 연관관계에 있는 엔티티의 정보 조회 N번)
해결책 1. (기본) Fetch 옵션 지연로딩 사용 (@OneToMany 기본값을 바꿔주기)
해결책 2. (+본질적 해결) Fetch Join : JPQL에서 JOIN시 JOIN FETCH하기
해결책 3. (+본질적 해결) @EntityGraph : 특정 메서드에서 어노테이션을 통해 특정 속성들만 EAGER로 설정하여 정보를 한 번에 들여올 수 있도록 설정.
+ 페이징 문제
해결책 : 엔티티 해당 컬럼에 @BatchSize 설정해서 한 번에 불러들이는 정보에 제한을 둔다.
'Programming > Spring, SpringBoot' 카테고리의 다른 글
| Querydsl (1) | 2024.02.06 |
|---|---|
| 낙관적 락 & 비관적 락 (1) | 2024.02.05 |
| [JPA] 영속성 컨텍스트 (Persistence Context) (0) | 2024.02.05 |
| @Query (1) | 2024.02.01 |
| Relations (M : N 관계) (1) | 2024.02.01 |







